|
Alta implements the nested process model in a Java Virtual Machine. To accomplish this merger both the process model and the virtual machine's existing execution model were modified.
To implement a process abstraction in Java, Alta introduces new core objects to Java. Existing Java objects that provide rudimentary support for separation and control, such as the ClassLoader or ThreadGroup, are insufficient. SectionĀ will explain how ClassLoaders do not provide the level of control over the name to class binding that is required by Alta. ThreadGroups in Java are merely a convenient mechanism for stopping a related group of threads. Adding the memory control, IPC and disjoint typespaces required by Alta on top of existing Java classes would prevent Alta from being backward-compatible with existing Java applications. For example, making the ThreadGroup the process container would fundamentally alter the meaning of creating a new ThreadGroup.
This chapter is divided into two parts: an overview, in six parts, of the design of Alta, followed by a detailed analysis of those six features.
This section outlines six features of Alta, compares them with similar features found in traditional JVMs and Fluke, and then sketches a short motivation for each. FigureĀ3.1
|
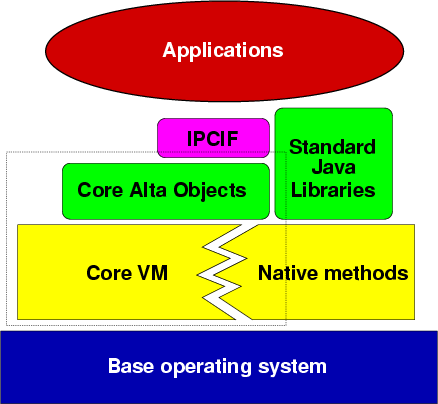
The Alta kernel is represented by the components inside the dashed box on the left side of the figure. Crossing this boundary is effectively equivalent to a kernel system call trap in a traditional operating systemĀ[5].
The first goal for Alta is to provide the illusion of a complete Java virtual machine to each process in the system--just as any operating system strives to convince each process that it owns the whole machine. In Java, preserving this illusion requires that each process have its own set of static variables, its own set of classes, and its own set of basic objects (such as System.out, a root thread group, etc.).
To support the nested process model, the Alta class loading mechanism gives a parent process complete control over the binding of fully qualified class names (such as "java.io.File") to class files. The mapping of class names to class files in a process defines the typespace of that process. In Alta, each process has its own private typespace. The parent process is responsible for resolving requests to bind a class name in a child's typespace.
Even though different processes may have disjoint typespaces, the virtual machine has sufficient information to allow safe sharing of objects between processes. Allowing processes to share fine-grained objects efficiently and safely is potentially critical to the performance of a safe, language-based operating systemĀ[49]. Interprocess sharing is naturally in conflict with process separation and complicates resource control. The hierarchy of the nested process model provides a simple mechanism for processes in Alta to control the degree of separation (and conversely the degree of sharing) in the system.
The low-level nested process model API is presented to Java applications as the set of classes in the package edu.utah.npm.core, defined in AppendixĀA. Implementation of the code supporting this API--the kernel code--required similar techniques for protecting it from user processes as are required in a traditional kernel. Additionally, this API is based on the original API designed for Fluke, with modifications to account for Java in the following three areas. First, processes may send Java object references through IPC; second, memory management is accomplished at a higher level of abstraction in Alta; third, Alta does not support state extraction or injection for any kernel objects.
The major design goal for Alta is to provide a framework for comprehensive resource accounting and control to Java processes. The two core resources explicitly managed by the kernel in the nested process model are memory and CPU. Alta was designed to account for as much of the memory used by a process as possible. For example, the memory used to retain the JIT version of a method is stored in memory charged to the process that performed the JIT compilation. The nested process model specifies a flexible CPU management scheme, CPU inheritance schedulingĀ[23], which I have not implemented in Alta. CPU inheritance scheduling appears to be a good match for Alta but the implementation effort to support it is beyond the scope of this thesis.
The Alta IPC-based interfaces are based around the native methods used by the core Java libraries. That is, the IPC-based interfaces have been tailored to the requirements of the core Java libraries. Native methods have been grouped and interposition is accomplished on a group basis. For example, there is a group of operations for the file system, a group for individual file I/O, a group for memory management, etc. The grouping of the IPC-based interfaces in Alta is comparable to the grouping of the POSIX oriented, IPC-based interfaces in Fluke.
Fluke supports the full extraction of kernel object state, which is critical for complete virtual memory managers and multi-process checkpointersĀ[46]. Alta does not support exportable state of kernel objects. The type-safe extraction of a thread stack is well beyond the scope of this thesis (and perhaps impossible). Support for fully exportable state is required for a number of user-level services but, as Alta demonstrates, it is not a critical component of the nested process model.
This section provides a detailed review of each of the six areas outlined in the previous section. Features that are derived from existing Java virtual machines are compared to those found in JVMs; features that are derived from traditional operating systems are compared to those found in Fluke and other traditional systems.
Alta processes are designed to run whole Java applications, unmodified. All of the services and capabilities available in a traditional Java virtual machine are available to each process in Alta. Each process has its own root java.lang.ThreadGroup, its own root java.lang.ClassLoader, and any process may define its own classloaders. All threads in the system are associated with exactly one process, memory is divided on a per-process basis, and each process defines a typespace. Finally, each process owns a port reference, called the keeper port, where the process can make initial requests for services, resolve names in its typespace; and signal when all its threads have died.
In Alta, each process has its own copy of the static data associated with a class, maintaining the illusion that each process has a separate virtual machine. Static data is associated with a class but not with any instance of that class. In existing Java virtual machines, static data is effectively global data (though visibility of the data may be controlled by language-level access modifiers, such as private).
As an unfortunate side-effect of the per-process static data and the separate typespaces, each process in Alta maintains its own copy of JIT (Just In Time) compiled methods. (Typespaces are explained in the next section.) The JIT compiler in Kaffe--the virtual machine Alta is based on--inlines static variable references into generated code. Thus a reference to the static variable java.lang.System.out in a method would be JIT-compiled into a direct reference to the address of the java.lang.System.out static variable. Additionally, separate typespaces mean that class hierarchies may differ between typespaces, and the compiled methods must reflect this difference. Per-process JIT compiled methods are effectively equivalent to using statically linked binaries in traditional operating systems. Changes to the JIT compiler in Alta to make static variable accesses indirect and to share code between equivalent typespaces are areas for future work.
Separation of processes is the cornerstone of resource control in Alta. Resources are allocated on a per-process basis in Alta, and the distinction between processes is critical for accounting resource consumption and release.
Given that processes are separated, the system must provide a facility for interprocess communication (IPC). Alta uses the IPC semantics specified by Fluke. Thus, while each process is presented with the illusion of running in its own Java virtual machine, facilities for discovering and communicating with other processes in the machine are available.
Alta extends the nested process model to encompass Java's classes. Classes are Java objects that define the object layout and object methods available in a typespace. Control over the typespace of a process provides the ultimate control over that process and enables parent processes to exercise precise control over resource accesses and to effectively "download" resource management into a child process.
A class is defined by a set of class files. The class file format, defined in the Java Virtual Machine specificationĀ[32], specifies the external representation of a class.1 This format allows classes to be stored and transferred between Java virtual machines. A class file symbolically specifies a superclass, fields, and methods. Class files can be dynamically loaded into the system, which extends the set of classes at run-time. When a class file is loaded, the virtual machine resolves the symbolic references to other class files, performs a series of link-time checks to make sure that the resulting class obeys safety constraints, and creates a java.lang.Class object representing the new classĀ[32]. Resolution of a symbolic reference can cause additional class files to be loaded. The JVM specification defines which names are resolved and when during the loading, linking and execution phases of a class. Note that a class file is not required to be an actual file, it is just a sequence of bytes.
In Java, the default mechanism for resolving a symbolic name into the appropriate class file is to convert the symbolic name to a file-system-friendly format and look for it on the local file system. For example the name java.util.Vector is transformed to java/util/Vector.class, which should be found on the local file system. The JVM specification describes an extension mechanism for Java applications to resolve names by subclassing java.lang.ClassLoader. Resolution of a name can be delegated to another class loader (usually the system class loader)Ā[31]. Once resolution of a name is delegated, all names referenced from that class file are implicitly delegated, also. This implicit delegation preserves the consistency of the typespace. For example, given the partial definition of
|
class C public Related r; Ī
|
Alta adds a new level of context--the process--to the type system. Within a process the type rules are unchanged from a traditional Java virtual machine. The type rules between processes, needed for interprocess sharing, are discussed in SectionĀ3.2.3.
In Alta, when a process attempts to resolve an unresolved symbolic name, it performs an IPC to its parent process and the parent can reply with any class file to which it has access. Regardless of where the parent acquired the class file, that parent will also be responsible for resolving every name referenced by the class file. For example, in response to a request for the class file to bind to the name "java.io.FileInputStream" a parent could respond with the class bound to the name "java.io.FileInputStream" in its typespace or, perhaps, with the class bound to "edu.utah.npm.stubs.NoFileAccess." (For convenience, the parent may reply with a class object, the virtual machine then uses the appropriate class file information in the child.) In either case, all unbound names referenced by the given class file will also have to be resolved. With this mechanism, a parent process has complete control over the nonsystem classes in a child typespace. Implicitly, supporting this level of control requires that the name associated with a class file be per-process and independent of the class file. Substituting class files under different names requires no new link-time safety checks as current virtual machines must already perform all of the necessary link-time safety checks to prevent version skew problems. Modifications to the run-time type checks are discussed in SectionĀ3.2.3.
To preserve the integrity of the virtual machine, critical system classes are loaded into each process and bound to their "correct" names by the virtual machine before any process begins execution. Preloaded classes are fixed in the class namespace of a process. There are two kinds of critical classes in Alta. The first set of critical classes is those that define the "kernel" of Alta--all the classes in the edu.utah.npm.core.* package, defined in AppendixĀA. The second set of preloaded classes is the relatively small number of classes that are entwined with the operations of the virtual machine. Table
|
One complication related to allowing a parent process to control class loading is controlling access to native methods. Native methods are declared in a Java class file but are implemented in C. Access to native methods must be controlled because their code is not under the control of a parent process--native methods can potentially violate the nesting hierarchy. Many native methods, however, pose no problem. For example, the native array copy method, which copies the contents of one array into another, provides no special privileges to the caller. In contrast, a native method such as java.lang.System.exit(), which causes the virtual machine to terminate, implies a great deal of privilege.
As an example, the critical class java.lang.Class contains the static native method findSystemClass, which takes a String as a parameter and returns a Class object. This method is not implemented in Java, but in C; the virtual machine invokes the C function java_lang_Class_findSystemClass() when Java code invokes java.lang.Class.findSystemClass(). The simple name transformation that converts a Java native method name into a C function name implies that Alta applications only need to generate a class with an appropriate name to call into native code. Fundamentally, the problem of controlling access to native methods stems from the assumption in the virtual machine that the binding from a name to a class is static. The C code is written for a particular class with a particular name.
Native methods are a useful point for a parent process to interpose on a child. For example, interposing on the exit method and replacing it with a method that uses IPC allows a parent to transform the JVM termination function to a process termination function. In Alta, native methods are semantically grouped and defined separately from the classes that use them. This grouping simplifies interposition for a parent process because all of the relevant methods, and only the relevant methods, are grouped together in a single class. Since these methods are all native methods they are denoted with an "NI" in their name (for "Native Interface"). Specifically, when a parent wants to interpose on the exit method, the native interface java.lang.NI_Exit.exit() is interposed on. In Alta, java.lang.NI_Exit is a simple class that contains only an exit method. The default java.lang.System.exit() implementation calls out to java.lang.NI_Exit.exit(). If java.lang.System.exit() did not invoke java.lang.NI_Exit.exit(), but instead was a native method itself, then to interpose on this function would require a parent process to re-implement the whole java.lang.System class.
The complication introduced by native methods is best illustrated by an example. Consider a parent process ProcA. In order to contain its child processes, ProcA replaces the java.lang.NI_Exit class with a class that terminates the calling process and not the entire virtual machine; however, if a child of ProcA creates its own child, ProcC, and maps java.lang.NI_Exit in ProcC to a custom class containing a native method exit(), then when ProcC executes java.lang.NI_Exit.exit() it will invoke the native method that shuts down the whole virtual machine, circumventing the controls placed by its ancestor, ProcA. This exploit is only possible if the virtual machine does not make a distinction between the class bound to NI_Exit in ProcC and the class bound to NI_Exit in ProcA. In Alta, the critical distinction the virtual machine makes is based on the origin of the class files. The class file in ProcA was (assuming it should have access to the native method) loaded by the kernel from the local file system, whereas the class file in ProcC was created in the standard Java fashion for creating dynamic classes--calling Classloader.defineClass(). The assumption is that classes loaded by the kernel are more trusted than arbitrary classes, and a parent process can control a child's access to classes loaded by the kernel. So, in this example, ProcC would be unable to execute the native method associated with java.lang.NI_Exit.exit(), because ProcA denied its child processes access to the trusted class that does have access to the native method. Alta effectively binds native methods to only the trusted class that the native method was written to work with; no other class, whatever its name, may call that native method.
TableĀ3.2
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Because class objects in Java define both object layout and the object methods, control over a child's process classes means the parent process can exercise control over what code is available in a child process, and with careful use of the language-level protection mechanisms, can "download" code into a child. The replacement of java.lang.NI_Exit in the previous section is one example.
Despite the separate typespaces for each process and the extent to which a child typespace can differ from a parent's typespace, Alta still allows a limited amount of direct object sharing between two processes. Shared objects can be accessed directly in either process without indirection or other overhead. Initially, processes in Alta contain no visible shared objects;2 the first visible shared object must be passed through IPC. Subsequent objects can be shared through the first object, or passed through IPC.
Safe sharing is possible because the virtual machine has complete information about the typespaces of any two processes that wish to communicate, and the virtual machine can mediate the initial communication between any two typespaces. The Alta virtual machine uses this information to guarantee that a shared object has equivalent class in both typespaces. Additionally, since a shared object effectively opens a communication channel between two processes, Alta must ensure that all potential objects that might be communicated through a shared object are also safe. Classes that pass these two tests--class equivalence and safe potential sharing--define the set of objects one process may share with another.
If an object were to be shared between two typespaces with inconsistent classes, the integrity of the virtual machine would be lost. For example, given the classes BasicClass, KeyClassSafe, and
|
class BasicClass public KeyClass key; public String name; final class KeyClassSafe private Object magicObject; final class KeyClassUnsafe public int spoofMagic; Ī
|
Note that the inconsistency described in this example can never arise within a single process (or a traditional JVM) because each name in a class file--in this example, the name "KeyClass"--is resolved only once. In Alta, however, the names referenced by a class file may be resolved differently in different processes.
To determine if an object can be shared between two processes, the virtual machine must determine if the set of class files that define the class of that object are equivalent in both processes. A class is defined by more than just a simple class file; a class is defined by the class of each field, the classes referenced in method signatures, the class of the superclass, and all of the implemented interface types. A class file only describes how a class is constructed by listing the names of the class file describing each of the relevant parts. Thus, two classes are equivalent if and only if all of the class files used to describe all of the parts of the class are equivalent.
A single class file can be defined as equivalent between two processes if it is derived from a single class file in a common ancestor process. More formally, identify a single class file as the pair ßN, P±, where P is the process in which N is the name of the class file, and define the notation ßNc, C± ▄immßNp, P±3 as: the class file ßNc, C± was resolved by the immediate parent of process C, process P, responding to the name Nc with the class file bound to Np. A child process's class file, ßNc, C±, and the parent process's class file, ßNp, P±, from which it was derived are equivalent class files. More formally, this relation can be expressed as: ßNc, Child± = ßNp, Parent±ĀifĀßNc, Child± ▄ immßNp, Parent±. This relation simply states that if a parent process replies to a child process's name request with a given class file then the class file is the same in the parent and child, regardless of the names they give it. Because this relation between parent and child process class files is an equivalence relation, it is reflexive, transitive and symmetric. The transitive closure of the relation defines a relationship ▄, where ßNc, Child± ▄ßNp, Ancestor±ĀifĀßNc, Child± = ßNp, Ancestor±. Thus, for two distinct processes Pa and Pb the class files named Na and Nb in respective processes are equivalent if they share a common ancestor class file. The resulting class file equality relation, = can be expressed as: ßNa, Pa± = ßNb, Pb±ĀifĀ(ßNa, Pa± ▄ßN', P'±ĀandĀßN b, Pb± ▄ßN', P'±).
There are two aspects of Java which complicate this analysis: classloaders and interfaces. Classloaders were described in SectionĀ. Incorporating classloaders into the definition of a class file requires that the notion of a class name be extended. That is, a class file is actually identified, within a process, by the pair of name and classloader. Other than complicating the definition of a class name, this should have no impact on the definition of a class or on class equality. Interfaces are effectively abstract classes containing only abstract methods. Interfaces are treated as regular class file objects, and add no actual complications to the Alta type system.
Given this definition of class file equality, the class equivalence test in Alta is a simple recursive algorithm. Given an object to be passed through IPC, Alta determines the class of the object. Given the class in the source process's typespace, there must be an equivalent class in the destination typespace.4 Starting with the basic class file, each referenced class file must also be equivalent in the two typespaces. This test determines if two classes are equivalent in disjoint typespaces. Referenced class names are followed until a base shareable class is encountered. Base shareable classes include primitive types--which are by definition equivalent in all processes--plus a select subset of the preloaded classes. See TableĀ3.3
|
For example, if an instance of the class BasicClass (see FigureĀ3.3 from the beginning of this section) is passed through IPC, Alta finds the class that defines BasicClass in each process. The BasicClass class file references three other classes, java.lang.Object (the implicit superclass), KeyClass and java.lang.String. The base shareable classes, Object and String, are always equivalent in all processes, leaving KeyClass. The class file bound to the name KeyClass is looked up in each process. Next, assuming that class file is equivalent, all of the classes referenced in KeyClass are checked for equivalence.
Alta currently implements an even more restrictive subset of this algorithm. Alta only allows objects that are instances of base shareable classes or are instances of classes whose fields are all base shareable classes. This is all that has been necessary in practice, so far. If necessary, generalizing the implemented algorithm to the specified one should be straightforward. The only difficulty will be handling and tracking circular class file references in a class definition.
By separating the name of a class from its definition, Java's classes behave similarly to mixins. A mixin is an abstract subclass--a subclass whose superclass is not fixedĀ[10]. The mixin may be applied to any appropriate superclass. This is similar behavior to a Java class in that the binding of the superclass to a class is done at run-time. In Java class flies, however, the name of the superclass is fixed in the class. In contrast with mixins, in Alta every name specified in a class file, e.g., the field types and in the method signatures, is bound at run-time.
Simply having equivalent classes in two typespaces is insufficient for Alta to allow sharing. Because shared objects open up an unregulated communication channel between processes, Alta must ensure that arbitrary objects cannot be shared. For example, consider an object, X with a field "ref" of type java.lang.Object. If X is shared between two processes, then those processes may pass objects of any type through X by reading and writing from the "ref" field. Such arbitrary types may not be available or compatible in both typespaces, leading to corruption of the virtual machine. Even if all classes in the two typespaces are completely equivalent, in the face of dynamically loaded classes the virtual machine cannot predict if the typespaces will become inconsistent in the future.
The only object fields that the virtual machine can guarantee are safe are those that are not polymorphic or interfaces. For example, a field of class java.lang.String is allowable because the class is final--subclasses of java.lang.String are not allowed.5 For non-final classes, the virtual machine cannot know what classes might be shared by as-yet-unknown subclasses. Therefore, the virtual machine cannot allow shared objects to contain fields of polymorphic classes (or interfaces). Note that references passed through IPC do not need to be instances of a final class because the virtual machine is dealing with a specific instance of the class.
It should be noted that the class edu.utah.npm.core.ClassHandle, a member of the base shareable classes, violates this rule. The class contains a field of class java.lang.Class, which is not a safe class. The implementation of edu.utah.npm.core.ClassHandle, however, is trusted and never allows the shared Class field to be visible in more than one process. This sort of analysis--gauging the visibility and safety of potentially unsafe fields--is only viable with trusted classes.
One more limit is placed on classes to allow them to be shareable: the classes must not contain static variables. This restriction allows the JIT compiler to inline static variable addresses. Because a shared object contains a method dispatch table pointer (also known as a vtable) the JIT code is shared with the object. To guarantee that this code is consistent with what would be generated in both processes, static variable references are disallowed. This is not a strict requirement. Relaxing it would imply that the JIT compiler be modified to support indirect access to static variables.
One unusual side-effect of Alta's shared object model is that each process has its own Class object associated with each shared object. Thus locking an object's Class will not provide mutual exclusion across processes. This is important because methods that are both static and synchronized are defined to lock the associated Class object. This caveat, coupled with the restrictions imposed for safety, imply that arbitrary Java objects cannot be indiscriminately shared between processes. No existing Java class, however, is written to be executed in two different processes, so shared objects must be treated with some care in any event.
An additional side-effect of Alta's type model is that the binding between a class and its name is not fixed. This, combined with the fact that a single type can have two names in an Alta process, means that serialization of objects in a manner compatible to the JDK specification is difficult, as serialization depends heavily on representing a type by its name.
Direct object sharing poses problems for memory management and resource ownership. These problems are discussed in SectionĀ3.2.5.
Despite these limitations and caveats, many objects are safely shared by the code in Alta's kernel. For example, cross-process capabilities are actually implemented as direct object references. Additionally, the IPCIF protocols (described later in SectionĀ3.2.6) are able to pass many parameters as shared objects instead of marshaling their parameters into a byte buffer, copying the buffer and unmarshaling the parameters.
The Alta core API (see AppendixĀA) provides the most basic set of services to Java applications. Its implementation is equivalent in many ways to the implementation of a traditional kernel. The Alta kernel multiplexes the underlying system to multiple processes. Just as in a traditional system, the kernel in Alta must protect itself from errant and malicious applications. The Alta kernel is fully preemptive.
The majority of the nested process model core API is simple to support in Java since the kernel abstractions are entirely new to Java (e.g., ports, references, and processes) or easily match existing Java abstractions (e.g., threads). The only objects that are significantly difficult to provide in Java are the memory mapping objects.
In Fluke, the nested process model core API defines regions and mappings for mapping memory addresses from one process into another. Java has no language-level notion of memory addresses, and introducing such a notion merely to support these abstractions is unproductive. The IPC-based API in Fluke, however, defines a memory pool object that represents a much more abstract chunk of memory--effectively, just a size in bytes. In Alta, this higher level abstraction, the MemPool, is used to manage memory. When a new process is created, the parent process can create a MemPool to associate with that process. The memory pool is given an amount of memory, allocated from the current memory pool. When the process runs out of memory the process will make an IPC to the parent to invoke the garbage collector or request more memory.
While mempools are created and given a size by user-level processes, the details of the mempool are managed by the virtual machine; individual credits, debits, and availability checks are made by the virtual machine. Currently, Alta supports only a one-to-one mapping between processes and mempools. Supporting many-to-one and one-to-many relationships should be possible, but there is currently no motivation for such support. A future version of Alta, however, could support different types of memory, for example "wired" and "pageable" memory, and this distinction could be presented to applications through different mempools.
To maintain the integrity of the kernel's data structures in the face of arbitrary user code and user contexts, three basic issues must be confronted. All three involve unanticipated exceptions being thrown while a thread is executing kernel code. The kernel maintains a number of shared data structures that must be protected from inconsistencies that could be introduced if a thread were stopped in the middle of a kernel critical section.
First, the kernel must protect itself from java.lang.Thread.destroy() and from asynchronous exceptions thrown via java.lang.Thread.stop(). Thread.destroy() is a method on a thread object which stops the target thread dead in its tracks; Thread.stop() stops the target thread and throws an exception in that thread's context. The kernel protects itself by postponing stops and other interruptions when a thread enters the kernel. Postponed interrupts and stops are "posted" when the target thread exits the kernel. Traditional kernels use a similar tactic, only delivering signals to processes while they are executing in user modeĀ[33, p. 97]. In Alta, the transition from "user mode" to "kernel mode" is explicit in the code by use of the kernel-private methods Thread.startSystemCode() and Thread.endSystemCode().
The second issue facing the Alta kernel is running out of stack space during execution. This poses the same problems as interruption, but stack overflows cannot simply be "postponed." Upon entry to system methods, the available stack space is checked against a predefined limit, analogous to traditional, hardware-based kernels that run kernel code on a separate stack of fixed size that is "known" to be sufficient (usually 4k or 8k bytes). The stack size check is not yet implemented in Alta.
The final and most complicated issue the core Alta code must deal with is running out of memory while executing kernel code. Like stack overflows, out of memory conditions cannot be "postponed." Unlike entry-time stack checks, a check for sufficient memory at kernel entry time is insufficient as other threads in the system may use the memory before the in-kernel thread needs it. Alta approaches this problem by pushing as much memory allocation out of the kernel as possible. In fact there is no explicit object allocation in the Java portion of the Alta kernel. All of the system calls operate on state provided exclusively by user mode code. In addition to avoiding out of memory conditions within the kernel, this increases the precision of Alta's resource accounting. For example, when objects such as a port or thread are created by an application, all of the required kernel state is allocated and initialized--in user-space. In a traditional hardware-based system, kernel state and application state are usually quite separate. For example, a file descriptor in Unix is user-mode state associated with some separately allocated kernel state. Traditional kernels cannot allow the user to allocate kernel data structures. Alta, on the other hand, can take advantage of the fine-grained access control provided by Java's type system to attach private kernel state to application-visible objects.
|
public final class Space // A kernel-internal cross-process reference private final Link keeperPortLink = new Link(); // For the queue of threads active in this process private Thread sthreadQHead = null; private Thread sthreadQTail = null; // An internal rendezvous object for threads // in this process final Object stopCond = new Object(); // ... Ī
|
|
|
There are still areas of Alta's kernel that can trigger out of memory exceptions. First, verification and JIT compilation of kernel methods cause the virtual machine to allocate memory. These allocations could be avoided by preverifying and precompiling all of the kernel methods when a process is created. Second, the virtual machine dynamically allocates monitor locks as they are required. Since the kernel itself uses very few monitor locks, those that are used could be preallocated for the required kernel objects. These changes would make Alta's kernel completely allocation-free and would eliminate a whole class of errors and race conditions related to memory allocation in the kernel.
Processes in Alta are subject to comprehensive memory controls enforced by the virtual machine. Every allocation made by a thread is charged to the memory pool associated with that thread's Space. This accounting includes buffers to hold compiled bytecode, the per-space typespace map, every Java object allocated by a thread, etc. Every object in Alta has an owning MemPool associated with it. The MemPool is credited when the garbage collector returns an unreachable object back to into the pool of available memory. The garbage collector introduces a delay between releasing an object and reclaiming the memory used by the object. Type-safety constrains the system to never allow dangling pointers. Together these two factors constrain the system's ability to terminate a process and reclaim all of its memory: to completely reclaim all of a process's memory, none of the objects in that process can be reachable and the garbage collector must be invoked to reclaim the memory.
Resource accounting and control are complicated by the sharing of objectsĀ[29]. In traditional hardware-based systems, a page of memory can simply be revoked by the operating system: any processes that try to access that memory will fail. For example, if a process is killed by the system, all of its pages can be unmapped and reused. In a type-safe system, an object cannot simply be unmapped and reused if there are existing references, as the existing references would invite type-safety violations. In a hardware-based system, revocation can lead to the corruption of a single process, but in a language-based system type-safety violations can lead to the corruption of the entire system.
Given a process, A, that "owns" objects that are shared with another process, termination of the process A will not result in the reclamation of all of its memory as the other process will effectively keep that memory reachable. Alta allows object sharing because the hierarchy of the nested process model can be used to contain sharing in a natural and efficient manner. A processes in Alta can tightly contain its child processes or let them communicate efficiently via shared objects. In this way, the application can trade the ability to cleanly terminate a child process for more efficient communication with that process.
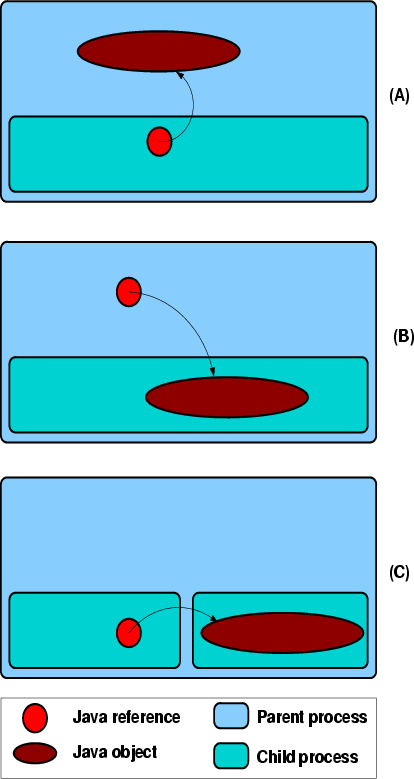
FigureĀ3.6 diagrams the three different types of interprocess sharing that can occur in the nested process model. In FigureĀ3.6(A), a parent process allocated an object and the child process has a reference to that object. In terms of process termination, this sort of sharing is harmless. If the parent terminates the child, all objects are reclaimed. If the parent is terminated, the child is necessarily terminated also. Additionally, this sharing paradigm is very useful: it is the standard server model, where the lifetime and usefulness of a server object depends on the lifetime of a client's references to that object. Of course, in this case, the server has lost the ability to reclaim the object unless it can convince the child to drop its reference or the child is terminated.
FigureĀ3.6(B) presents the case of a parent holding a reference to an object in a child process. Again, in terms of termination, this sort of sharing presents no significant problem. If the parent process terminates the child, the object is simply promoted to the parent--the parent effectively owns the whole child to begin with. Again, in this scenario, if the parent is terminated, the child is necessarily terminated also. This sharing format is, again, useful: a child could, for example, pass a reference to a local buffer to a
|
Finally, FigureĀ3.6(C) diagrams sibling processes sharing an object. Communication with a sibling process requires the cooperation of the parent as it is the first common communication endpoint. In terms of termination, by allowing two sibling processes to share objects directly, a parent process has linked the clean termination of those processes; in order for the parent to terminate one child process and reclaim all of its memory, the parent must necessarily terminate the other child process, too. In Alta the allocator of an object is charged. This tradeoff of clean termination versus fast communication is left to the discretion of processes in the system. Alta provides sufficient infrastructure for any process to implement these policies over the processes it is managing.
The Alta IPC-based interfaces, or IPCIF (see AppendixĀB), provide applications running on Alta with an interface to higher-level services than provided by the kernel. Except for the Parent interface (SectionĀB.1), the IPCIF API relies on the kernel only for the communication mechanism; the protocols are otherwise independent of the kernel.
In Fluke, the IPC-based interfaces support the POSIX orientation of the standard libraries Fluke applications are linked against. In Alta, however, the IPCIF are designed to support the Java standard libraries and are based around the native interfaces upon which those libraries depend (see TableĀ3.2). Despite the different focus, the interfaces are quite similar. Both systems have interfaces for accessing the file system--for example, opening a file or deleting a file--an interface for reading and writing individual files, and a memory management interface for requesting and returning large blocks of memory. Alta has an interface for memory related operations such as invoking the garbage collector and querying the amount of memory available. In both Alta and Fluke the Parent interface is the only interface to which a child process initially has access. This interface serves as the most basic name service, providing access to other interfaces. While the Parent interface is directly supported by the kernel (the Alta kernel invokes class name resolution requests on the parent interface directly), the other interfaces are completely independent of the kernel. This separation means that IPC-based interfaces can be tailored for specific environments or to support new server interfaces without changing the kernel.
Alta does not support the Abstract Window Toolkit (AWT) libraries at this time because the Kore library--the standard Java library implementation Alta uses--does not have working AWT support. Unlike the other IPCIF interfaces, the division into "server" and "client" components for the AWT has no analogue in Fluke. The best example of an IPC-based GUI is the X windowing system, so an AWT interface on IPCIF should be straightforward. The Kore library is described later, in SectionĀ.
One of the basic tenets of Fluke is that all state of all objects is extractable at all timesĀ[21,Ā46]. Actually, in Fluke, much of the associated kernel state is not exported when a kernel object is extracted. All that is needed to "extract" an object is enough information to correctly recreate the object later. Additionally, for many of the core kernel objects in Fluke, state is only extracted when the object is not in the "middle" of an operation. For example, the state of a thread object is extractable only if the thread is not executing any kernel functions. If the thread happens to be executing a kernel function when its state is extracted, the kernel functions are canceled and undone, and then the state of the thread is extractedĀ[21].
While wholesale state extraction is useful for writing a comprehensive checkpointer that can take a "snapshot" of a set of related processesĀ[46], and for writing a virtual memory nester that can write a process's kernel state out of core, state extraction is not useful for resource control and process management. It is important to note that services such as virtual memory and checkpointing are not impossible in Alta, but they must be implemented within the virtual machine.
The largest stumbling block to implementing state extraction in Alta would be the safe restoration of an exported thread's stack. A representation of a thread stack would have to be developed as well as a mechanism for verifying that each frame on the externalized stack matched the requirements of the associated method. Given that an externalized stack could be manipulated, the ability to "download" code into a child process would be jeopardized as a process could invoke trusted code, stop the thread, extract the thread's stack, manipulate the stack to a new state, and restore the thread, thus bypassing whatever checks may exists in the trusted code. Together these restrictions on complete state extraction outweighed the benefits and Alta was not designed to include state extraction.
Starting with the nested process model, as implemented in Fluke, Alta was created by mapping the model into a Java virtual machine. Alta gives each process the impression of running on its own Java virtual machine, yet still allows processes to directly share many types of objects. A process in Alta may control the types visible in child processes, and may maintain resource limits on those child processes. Finally, Alta uses a number of standard operating system techniques for maintaining control over user processes.