|
This chapter demonstrates some simple examples of using Alta, presents a quantitative analysis of Alta's implementation in terms of performance and relative size, and finally compares Alta and Fluke.
The Alta virtual machine supports the basic features required of a Java virtual machine such as garbage collection, threading, JIT compilation, bytecode interpretation, verification, and all of the features of the core Java libraries. The majority of these features were implemented by the software Alta is built upon: the Kaffe virtual machine and the Kore standard libraries.
The Alta virtual machine is based on KaffeĀ[51], a freely available virtual machine developed by Tim Wilkinson. Alta is based on Kaffe version 0.9.2, which supports most of the features of JDK 1.0.2 and used Sun's JDK 1.1.3 class libraries. For Alta, a large number of features introduced into later versions of Kaffe-such as an improved threading infrastructure and a new garbage collector--were ported back to Alta.
The core Java libraries for Alta are based on the implementation provided by the Kore projectĀ[13]. Kore is a clean-room implementation of the Java core libraries and is compatible with JDK 1.0. Kore provides a very clean and minimal interface between the Java libraries and the native code they depend upon.
The Alta implementation is reasonably small, both in terms of the changes made to the virtual machine (several thousand lines of code) and the runtime support code (several hundred lines of code).
The implementation of Alta is easily broken into two pieces--a Java component and a C component. The Java component consists of the core Alta libraries, which implement the basic NPM primitive objects. Also in the Java component are the IPCIF libraries that provide the high-level services on top of IPC. The core library is approximately three thousand lines of code (three kloc), while the IPCIF library is less than two kloc.1 As a point of reference, the Kore library, which provides standard Java libraries compatible with JDK 1.0.2 but without AWT support, is about four kloc, while the JDK 1.1.7-compliant standard Java libraries for Kaffe v1.0b2 without including AWT support is just under nine kloc.
The Kaffe virtual machine (version 0.9.2, on which Alta is built) contains approximately ten kloc of C source, while the Alta virtual machine weighs in at thirteen kloc of C source. Probably one-half of that increase is code that fixes bugs, adds significant debugging infrastructure or supports new features from later versions of Kaffe. For example, a new threading infrastructure was incorporated into Alta from a later version of Kaffe. Additionally, Alta, unlike Kaffe, provides native methods for the Kore libraries.
In terms of binary size, on FreeBSD 2.2.6 the Alta virtual machine binary is approximately 350K statically linked or 230K if the standard FreeBSD libraries are dynamically linked. A Kaffe version 0.9.2 binary is 350K statically linked or 200K dynamically linked. The 29 core Alta class files, i.e., the edu.utah.npm.core.* package, use 53K of disk space, the 28 IPCIF class files use 55K, while the Kore library's 163 files use 183K. In comparison, the JDK 1.1.7-compliant standard Java libraries for Kaffe v1.0b2 contains 532 class files and requires about 915K of disk space and the Sun JDK 1.1.6 core runtime (all of the java.* packages) contains 721 class files that require 1.6 megabytes of disk space.
Overall, Alta and its libraries are moderately sized, and the changes made to the virtual machine are not overwhelming.
Java is a simpler and safer language than C. The Java compiler catches far more errors than any C compiler. On the other hand, the high-level nature of many of the basic Java abstractions occasionally hampers the system programmer. For example, because java.lang.String objects are real Java objects, using them in critical parts of the kernel (e.g., for debugging) can be troublesome. Specifically, the class name resolution code that performs an IPC to a parent process cannot print a String because the compilation of String methods may cause recursive entry into the IPC class name resolution code. One other example of the lack of system-level control while programming in Java is evident when allocating temporary objects. In C, a struct local variable is allocated on the stack, but there is no such analogue in Java: all Java objects are dynamically allocated on the heap. Stack allocations are a fast and simple way of avoiding the overhead and errors associated with dynamic memory allocation and such techniques can be critical in a kernel. In Alta, only one allocation in the kernel needed to avoid the heap allocator. In C this site would have used stack allocation; in Alta this need was addressed by dynamically allocating the object in the context of the caller--avoiding the heap allocator in the critical code. Just as C programmers can delve into assembly for truly low-level control over a system, a Java systems programmer always has the option of using C code for implementing constructs that are awkward or inefficient in Java.
Alta is invoked in the same manner as other Java virtual machines. The only required argument to Alta is the name of the initial class to load. Optional arguments can be provided before the class name. Arguments given after the class name are arguments to the main() method of the initial class. Class files are found on the local file system via the CLASSPATH environment variable.
Here is the traditional "Hello World!" example for Alta:
Hello World!
Ī
Ī
Alta loads the class file HelloWorld.class and executes the static main() method in HelloWorld which simply prints the string "Hello World!" to standard output.
The next example demonstrates how to run HelloWorld as a subprocess of the Alta sandbox. The Alta sandbox was described in sectionĀ1.1.
Hello World!
Ī
Ī
In this example, "HelloWorld" is the name of the application the sandbox starts. The sandbox is an Alta application that creates a child process and optionally regulates the child's access to classes, the file system, etc. In this example, the sandbox only interposes on class name resolution but does not limit file system access or memory usage.
As a more complex example, the following fragment is a trace of javac, the Sun Java compiler, in a sandbox. The compiler compiles the Java source file HelloWorld.java into the file HelloWorld.class.
sun.tools.javac.Main -verbose HelloWorld.java
[parsed HelloWorld.java in 314ms]
[loaded /lib/classes.zip(java/lang/Object.class) in 39ms]
[checking class HelloWorld]
[loaded /lib/classes.zip(java/lang/String.class) in 20ms]
[loaded /lib/classes.zip(java/lang/System.class) in 14ms]
[loaded /lib/classes.zip(java/io/PrintStream.class) in 10ms]
[wrote HelloWorld.class]
[done in 965ms]
Ī
Ī
Note that the -verbose flag is passed to javac and causes javac to print out the time required to perform various steps of the compilation. Again, the sandbox nester is not interposing on any interfaces.
The next example demonstrates that the sandbox application can be nested, creating a trivial hierarchy of nested processes. This is feasible because the sandbox nester relies on the same interfaces that it exports.
edu.utah.npm.apps.sandbox.Main HelloWorld
HelloWorld!
Ī
Ī
The final example demonstrates the result of running the java compiler with a restricted memory pool. The -memlimit argument to the Alta sandbox specifies the size of the memory pool for the compiler. Because the limit given is less than the working size of the compiler, it runs out of memory and is cleanly killed by the sandbox.
Note that each time the child runs out of memory, it faults to the sandbox. The sandbox never increases the size of the child's mempool, it simply prints a message and invokes the system-wide garbage collector. When the size of the child's working set exceeds the memory pool, the sandbox nester terminates the child.
sun.tools.javac.Main -verbose HelloWorld.java
[parsed HelloWorld.java in 316ms]
Child ran out of memory (short by 9496)
[loaded /lib/classes.zip(java/lang/Object.class) in 144ms]
Child ran out of memory (short by 12656)
[checking class HelloWorld]
[loaded /lib/classes.zip(java/lang/String.class) in 20ms]
Child ran out of memory (short by 1080)
Child ran out of memory (short by 152)
[loaded /lib/classes.zip(java/lang/System.class) in 118ms]
Child ran out of memory (short by 344)
Child ran out of memory (short by 168)
[loaded /lib/classes.zip(java/io/PrintStream.class) in 114ms]
Child ran out of memory (short by 1568)
Child ran out of memory (short by 9536)
Child ran out of memory (short by 152)
Child ran out of memory (short by 176)
Child ran out of memory (short by 8744)
Child ran out of memory (short by 5416)
Child ran out of memory (short by 1432)
Child ran out of memory (short by 1432)
Working set exceeds memory limit. Child terminated.
Ī
Ī
I compare the performance of four different virtual machines: the Alta virtual machine, two "stock" versions of Kaffe, and a Microsoft Java virtual machine. The Alta virtual machine is based on Kaffe v0.92 but incorporates many of the changes that brought Kaffe to v1.0b2, thus the Alta virtual machine lies somewhere "between" these two stock Kaffe virtual machines. Alta uses the Kore class libraries while Kaffe v0.92 uses Sun's JDK 1.1.3 class libraries. Kaffe v1.0b2 uses its own custom set of class libraries; as does the Microsoft virtual machine. Benchmarks where the differences between the class libraries are likely to make a performance impact are so noted. TableĀ4.1 shows each virtual machine, its libraries, and approximate JDK version. Note that for the Kaffe and Kore libraries compliance with the given JDK version is not complete.
|
All results reported in this chapter were obtained on a 300Mhz Intel Pentium II CPU with 128Mb of main memory and a 512K L2 cache. This architecture includes a 16K L1 instruction cache and a 16K L1 data cache. The system was running an installation of FreeBSD version 2.2.6, with only the necessary system services active. The Microsoft JVM results were obtained on an identical machine running Windows 95 using the Microsoft Java virtual machine shipped with Visual J++ v6.0.
All of the Java virtual machines measured in this chapter support JIT compilation. When appropriate, tests were written to avoid including the time used by the JIT compiler in the results. For tests that measure whole-application performance, JIT compilation was necessarily included. Additionally, garbage collection was prevented during timing loops by cleaning the heap before a timing loop and ensuring that sufficient space for dynamic allocation requests was available.
For Alta, CPU usage is measured with the Pentium cycle counter.2 The cycle counter provides a very accurate, low-overhead measure of processor time. It is directly accessible in a processor register from user-mode. For the stock versions of Kaffe, the standard method java.lang.System.currentTimeMillis() was modified to return the current value of the cycle counter instead of the current time in milliseconds. For the Microsoft virtual machine, the "PIT timer" was accessed through the Win32 kernel function QueryPerformanceCounter(). This timer fires 1,193,180 times per second. That translates to just over 251 cycles per PIT clock cycle on a 300Mhz machine. The Microsoft virtual machine numbers are reported as a number of clock cycles derived from the measured number of PIT ticks.
I present performance benchmarks of a number of distinct features of Alta: object allocation, thread-switching, IPC, process creation, and file-system read/write. For those features that are available in a basic Java virtual machine, performance is compared to stock versions of Kaffe and to a Microsoft Java virtual machine.
These comparisons serve two purposes. First, they compare the Kaffe-based virtual machines to the Microsoft virtual machine, an aggressively optimizing virtual machineĀ[48,Ā54], highlighting areas where Alta and Kaffe could be improved in general. Second, by comparing with the base versions of Kaffe, these micro-benchmarks provide insight into the cost of supporting multiple processes in Alta, with respect to small, specific operations.
The first set of benchmarks measure basic features of a virtual machine: assignment, run-time type checking, and method invocation. Each operation was repeated (10,000 times) and the total cost of the experiment was divided by 10,000. Results from 34 of these trials were averaged (and rounded to the nearest whole cycle) to get the numbers shown in TableĀ4.2. For all of the results in this table, the range covered by the thirty-four trials was never more than eight cycles. Architectural artifacts such as cache effects, branch target alignment, mispredictions and memory stalls can easily generate timing variations on the order of 15 cycles, so results and deviations less than about fifteen cycles should simply be read as "real small."
|
Two conclusions can be drawn from these results. The first, and most important, is that the performance of basic features of the virtual machine are not significantly changed by supporting multiple nested processes. The two discrepancies are assignment to an Object array (the fourth line of the table) and synchronized method invocation (the last line of the table). Assignment of an object into an Object array is slower in Alta due to the changes made to the type system. These changes also impact the "instanceof (same)" benchmark, which measures the cost of Java's instanceof operator. Both benchmarks include a runtime type check; because Alta has a slightly more complex notion of type than a traditional Java virtual machine, Alta takes slightly longer. The synchronized method invocation benchmark slows considerably in the later version of Kaffe due to changes in the locking primitives. Note that the 1.0b2 version of Kaffe includes optimized method invocation and optimized runtime type checking.
The second conclusion that can be drawn from these results is that Alta is substantially slower than the Microsoft virtual machine. Compared to the Microsoft virtual machine, the Kaffe-based virtual machines take three times as long to invoke instance methods, three times longer to invoke synchronized methods, and about twice as along to do everything else. This result implies that the absolute performance of the Kaffe-based virtual machines could be dramatically improved by optimizing the most basic primitives.
|
Continuing with benchmarks of basic virtual machine operations, TableĀ4.3 presents three measurements of thread overhead. The first row presents the cost of switching threads using Object.wait() and Object.notify(). The second row presents the cost of switching threads using the Thread.yield() call. Both of these tests create optimal conditions: the threads do nothing but switch back and forth. The wait/notify test measures thread switching overhead in the case of two threads that are trying to synchronize with each other. The yield test measures thread switching overhead for the case of threads that are simply sharing the same processor.
The third row of TableĀ4.3 shows the time taken to start a new thread. This test measures the time from the invocation of Thread.start() to the beginning of the run() method in the target thread--it does not include the time to allocate the thread object. It should be noted that the locking and thread switching in Alta have been optimized with aggressive inlining and lock caching and the results for Kaffe v1.0b2 could be trivially brought in line with Alta's results as both virtual machines use the same threading package. (Kaffe v0.92 on the other hand, uses a completely different threading package.)
Kaffe's thread support is written as a user-mode thread package implemented with sigsetjmp() and siglongjmp(), while the Microsoft virtual machine uses kernel threads. Comparing a user-mode implementation to a kernel-mode implementation is usually a comparison of "apples to oranges," but Kaffe's thread package correctly uses nonblocking I/O operations to mitigate most of the shortcomings of a user-mode thread package, which eliminates the major distinction between user-level and kernel-supported threads. On the other hand, by using a user-mode thread implementation, Kaffe cannot simultaneously schedule threads on multiple CPUs.
These benchmarks show that support for nested processes has not impacted the thread scheduling primitives of the Java virtual machine. It must be noted, however, that the nested process model's thread scheduling model, CPU inheritance scheduling, has not been implemented in Alta.
The next set of benchmarks measure the time to allocate an object. Alta adds a single 4-byte pointer to the per-object overhead and charges each allocation against the appropriate memory pool. To better quantify this overhead, additional Alta results are obtained with memory pool support completely removed--that is, Alta was compiled without the per-object overhead and without the memory accounting code included. Like the threading support, object allocation in Alta has been optimized--mostly through aggressive inlining. For comparisons to Kaffe, Alta's GC system is closer in lineage to the later version of Kaffe.
|
As shown in the first two columns of TableĀ4.4, the per-object accounting scheme in Alta adds an overhead of 50 to 150 cycles to the allocation cost of a basic object. There is significant overhead for the allocation of the kernel-managed core objects when memory pool support is enabled, as seen in the rows for the core Reference(), Cond(), Mutex(), and Thread(). For these objects, the overhead of memory pool support is approximately 2500 cycles (about 8us on a 300Mhz machine). These extra cycles are used to register the core object with the owning memory pool so that when the memory pool is destroyed the core objects will be properly cleaned up and destroyed. Note that IPCPayload and ClassHandle are not "core objects," they only exist to simplify passing parameters to and from some system calls.
While there is a much more substantial overhead for core objects, these objects are generally allocated only when starting up new processes or threads. Additionally, the code that registers core Alta objects is written in Java and would benefit from improvements to bytecode compilation.
To reduce the overhead (both in time and space) of charging each object to a memory pool, a virtual machine could charge a memory pool on a per-page basis and allocate multiple objects out of the page. This approach has the advantage of reducing per-allocation costs by amortizing them over the number of objects in a page, but has the disadvantage of increasing the memory usage of an application because the application would be required to pay for an entire page of objects, even if only one or two objects are allocated on that page. Despite these shortcomings, this approach would probably bring an improvement to the per-object accounting overhead. This cost is compounded in virtual machines, such as Kaffe, that predivide pages into similar sized objects. Notice that this optimization would not greatly reduce the overhead associated with Alta's kernel objects.
In summary, while there is a measurable overhead to per-object accounting, it is insignificant for basic objects. For kernel objects there is a more significant cost.
This section provides a breakdown of the interprocess communication (IPC) costs in Alta. The single number that all the other results in this section revolve around is 18,524 cycles (just under 62us on a 300Mhz machine): the time required for a complete, local, null IPC. Specifically, finding a server thread from a port reference, connecting to the server, sending a null request and receiving a null reply and then disconnecting. To put this measurement in perspective, a null IPC in Alta is almost eight hundred times more expensive than a method invocation. Like all of the IPC results in this section, this number is the average of 34 trials. Each trial makes 10,000 repeated null IPCs and divides the time taken by the number of iterations. The standard deviation of the 34 null IPC trials is 83 cycles.
As a point of comparison, a Fluke kernel with the "same" IPC path completes a null IPC in about 7,500 cycles. A more detailed comparison between Alta and Fluke is made in SectionĀ4.4. The most recent incarnation of Fluke, which contains a completely rewritten IPC path can complete a null IPC in about 3,800 cycles.
In addition to the null IPC benchmark, I present results for copying data through IPC, sharing objects through IPC and a breakdown of costs along the IPC path.
4.3.1.0.0 IPC with data. Two slightly more complex IPC benchmarks are the time to marshal, send, receive and unmarshal 3 integers and the time to marshal, send, receive and unmarshal a 100-byte java.lang.String. Alta requires about 22,000 cycles to send three integers, implying that it takes on the order of 3,500 cycles to marshal three 32-bit integers into a byte buffer, copy the byte buffer from client to server, and then unmarshal the three integers from the byte buffer. Transferring a 100 character String through IPC requires about 31,000 cycles, implying that an astounding 12,500 cycles are required to convert a String to an array of 100 bytes, copy the 100 bytes, and convert them back to a String.
|
To verify this overhead, two benchmarks that attempt to measure the non-IPC computations were run on all of the virtual machines. The first benchmark marshals three integers into a 12-byte array, copies the byte array, and unmarshals the three integers out of the array. The second benchmark marshals a 100-byte String into a 100-element byte array, copies the byte array, and unmarshals a String from the resulting byte array. TableĀ4.5 displays the results. Note that all four virtual machines use a different class library, and much of the difference in the String benchmark could be due to the performance of the String class's implementation. The Microsoft virtual machine is probably optimizing the integer constants out of the loop in the "Integer marshal" benchmark and might be inlining the array copy in both benchmarks. The discrepancy between the numbers in this table and the estimates in the previous paragraph is quite noticeable. There are 3,000 "missing" cycles for the integer benchmark and 4,500 "missing" cycles in the String-copy benchmark.
Notice that the performance gap between the Kaffe-based virtual machines and the optimizing Microsoft virtual machine has increased relative to the difference in previous benchmarks. More Java code is used in the benchmarks, so the Microsoft optimizer has more code to work with.
4.3.1.0.0 Sharing via IPC. Another way to send a 100-character java.lang.String is to send an object reference through IPC. Doing so with Alta requires about 20,000 cycles--1,500 more cycles than a null IPC, but about 11,000 less than marshaling and unmarshaling the String data.
The benefit of copying or sharing smaller data items is overshadowed by the relatively high cost of IPC in Alta. If Alta's IPC logic were significantly faster, the cost of a data copy (which is basically fixed by the processor) would be a more significant contribution to overall IPC time, and thus sharing data through IPC would be more appealing (as IPC will always have a nonzero cost). Still, the advantages of sharing a complex object and thus avoiding IPCs will always be appealing. For example, a shared object representing an open file could correctly keep track of the number of bytes available in the file and entirely avoid an IPC on available() calls.
|
4.3.1.0.0 IPC cost breakdown. TableĀ4.6 shows a breakdown of where time is spent in a null, round-trip IPC. The first column identifies the stage of the IPC; the next two columns show the timestamp, in cycles, from the beginning of the sequence and the difference from the last step, respectively. The last column describes the state the thread is in and what it is doing. The entries in bold font are the obvious bottleneck candidates. Additionally, the absolute times in this table include the act of recording timestamps in the critical path, and thus the overall execution time is inflated. Specifically, before exiting an IPC system call there is at least an additional 2,500 cycles of overhead to write back the set of timestamps from the IPC call; this overhead is only explicitly recorded in step 7 where the server thread is finishing its previous IPC call. Also, when entering an IPC system call 700 cycles are required to initialize the timestamp buffer for recording; again, this overhead is only recorded in step 7 when the server thread starts a new IPC operation. (For the client, IPC system call entry overhead is recorded before step 1 while the exit overhead occurs after step 16.)
The five highlighted stages (stages 4, 7, 8, 11 and 15) are the obvious bottlenecks candidates. Before explaining the bottleneck candidates, the costs incurred by the other stages should be examined. First, consider the cost to get to stage 2 from stage 1--374 cycles. Even allowing 200 cycles for the timestamp code,3 a lot of cycles were used just to get from the function entry point to the first timestamp before any "real work" gets done. In fact, there are only (in the Java source) two assignment statements and three conditionals (one while-loop test and two if statements) between the two stages. An explanation for this slowdown--the poor performance of the Kaffe compiler--will be discussed later, in SectionĀ.
The bottleneck candidate stages all involve finding a thread, "capturing" a thread or switching to a different thread. Threads can be "captured" by other threads in the kernel--the target thread is removed from its wait queue, implying that it will not be woken until the capturing thread explicitly wakes it or re-queues it. These parts of the Alta kernel contain the heaviest use of synchronization. Steps 7 and 15 include a thread switch and the best-case cost of a thread switch is 540 cycles (for a wait/notify-style thread switch). Of course, the middle of the IPC path is clearly not a best-case thread switch.
Additionally, by adding instrumentation code to the IPC path, the overall execution time of a null IPC was increased by roughly 7,000 cycles (3,200 of which are accounted for in stage 8), so in reality, the costs of each stage are somewhat smaller. Because the majority of the IPC code path is implemented in Java, improvements to the bytecode compiler would directly improve the performance of Alta's IPC.
The thread synchronization code in the bottleneck stages is a layer built, in Java, above the low-level synchronization primitives used within the virtual machine. By integrating the features required by the IPC code into the low-level synchronization primitives, the performance of the bottleneck stages should improve.
One result implied by the IPC code breakdown is that even simple operations are expensive in Alta. The code fragment presented in
|
int simple(int ops, int rc) while (ops != 0) if ((rc != 0) && (rc != 0x0F)) return rc--0xFF00; if ((ops & 0x100) != 0) ops = ops & Ā0x100; else if ((ops & 0x200) != 0) ops = ops & Ā0x200; return 0; Ī
|
|
Because gcj is not complete enough, as of this writing, to compile any useful portion of Alta's Java source, comparisons of the run-time differences for the compilers cannot be presented. Given the number of memory references made by the Kaffe-generated code, and the size of that code, it seems obvious that a significant gain in performance could be obtained by improving Alta's JIT compiler. Note that a JIT is not intended to rival the quality of code generated by an optimizing ahead-of-time compiler.
Alta can create a nested process in approximately 39ms (11.9 million cycles). The cost rises to 42ms if the cost of allocating and initializing the various objects required by the parent is included. The cost is measured as the timestamp difference from the parent process's call to edu.utah.npm.core.Space.startMain() to the entry to the child process's main() method. 39ms is an average of 11 trials which have a standard deviation of less than 1ms. The time to start a child includes the time to fault in 26 classes including basic I/O classes, simple exceptions, and other miscellaneous classes.
In comparison, an Alta thread is created in about 0.2ms (see SectionĀ), and a fork() and exec() of a very simple C program under FreeBSD takes about 0.7ms. Using java.lang.Process.exec() (based on FreeBSD's fork() and exec()) to start a new Kaffe process from within Kaffe requires approximately 300ms. Because a large portion of the time spent starting a new Alta process is used to fault in the most basic classes, moving to a static definition of a process's typespace would probably improve the performance of process creation greatly (see SectionĀ5.3). Additionally, unlike fork-and-exec in FreeBSD, which can simply share the executable's memory image between a parent and child, Alta re-links every critical class object in the context of the new process. Again, the cost of Alta's very dynamic class loading mechanism could be mitigated by using a more static definition of a process typespace. Lastly, the compiled code in Alta is process specific and thus this benchmark includes the time to compile and execute all of the methods invoked before main()--a number of constructors and java.lang.ThreadGroup.add().
To estimate the cost of interposition, two different scenarios are measured. First, the cost of interposing on the class name resolution of a child process is measured and second, the cost of interposing on the file system access interface is measured. Both of these tests use the Alta sandbox, a simple application that interposes on the parent interface, for class loading and memory control, and on the file system and file I/O interfaces.
First, to measure the cost of interposing on class name resolution, I executed, in the Alta sandbox, a simple program that dynamically loads a fixed number of classes. The loaded classes are minimal and require very little run-time initialization, so the time recorded for loading such a class should be dominated by the overhead of class loading. Running this test case as a child process of the sandbox measures the overhead of loading a class by faulting via IPC to a parent. These tests measure the worst case for loading a class because the class is not already loaded into the parent process. Table
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
To test of the impact of interposition on actual application performance, Sun's Java compiler (a Java application) was run on Alta, under nested sandbox applications. The sandbox server interposes on the class loading interface, the file system interface and the file I/O interfaces. The sandbox does nothing but pass the interposed request on, so these results measure the minimum overhead for interposition. The compiler was given 24 different, small files to compile. TableĀ4.10 shows how long it took (in milliseconds) to compile the 24 files when the compiler is nested within zero to five sandbox processes. The times reported are an average of 34 trials and do not include the cost of starting the virtual machine, only the time from the invocation of the compiler's entry point to the invocation of java.lang.System.exit() Note that JIT compilation of the compiler and some GC time are included. Each additional level of nesting adds a fairly constant cost of 400ms to the compilation time. The most important aspect of this result is that the interposition costs in this table grow linearly with the number of interposition levels. 4.4 Comparison with FlukeComparing Alta to existing virtual machines provides a sense of the cost of adding processes to a Java virtual machine, but how does the system compare to existing, hardware-based operating systems? Because Alta is based on the OS model developed for the Fluke operating system, Fluke is the obvious choice for a comparison. This section begins with a comparison of how well the model from Fluke was able to map into Java, explains some of the differences and then presents some quantitive comparisons. 4.4.1 Implementation comparisonObviously the interfaces and their semantics are borrowed from Fluke, but Alta also borrows structure from Fluke's implementation. For example, Alta's IPC implementation is, in large part, a Java translation of Fluke's IPC implementation (written in C). Many of the kernels internal structural details are similar. For example, Fluke's internal relationships between threads, ports, port sets, and IPC is maintained in Alta. Internally, the Alta kernel represents objects with the same structure as Fluke, but Alta takes advantage of Java's support for objects. This structural similarity between the systems enables comparisons between the programming languages and their relative applicability to writing system software. The current state of Java code compilation, however, makes a comparison of the performance of Java versus C in system software untenable. The results in SectionĀ demonstrate that there is potential for significant improvements in Java compilation in the near term. Additionally, the Alta kernel is written in more of a C coding style than a highly object-oriented Java style, so kernel code should not suffer unduly from overhead due to dynamic dispatch--a traditional bottleneck in highly object-oriented systemsĀ[3]. While a lot of functionality was copied from Fluke, not all of Fluke's features were implemented in Alta. For example, Alta only implements reliable IPC and does not (yet) support the best-effort or at-least-once IPC mechanisms supported by Fluke. Originally, I thought reliable IPC would be sufficient, but there are two places where at-least-once IPC (for idempotent operations) would improve Alta. First, if the class fault used it, then class faults could be triggered in the middle of reliable IPC operations that cause a new class to be loaded. For example, when a process sends an object to another process that does not yet have the object's class loaded. Additionally, at-least-once IPC would use less memory and thus be a better candidate for delivering out-of-memory signals to a parent memory pool. While Alta supports the Fluke condition variable and mutex objects, they are redundant with the native monitor support, via the synchronized keyword, in Java. Additionally, the kernel exceptions and per-thread exception handlers defined by the Fluke API are not required in Alta because of Java's native support for exception objects and exception handlers. One important and compelling difference between Alta and Fluke is the treatment of objects that have both kernel-private and user-accessible portions. To protect kernel-private data, Fluke uses "schizophrenic" objects that have separate kernel and user-mode portions. In most cases the user-mode object is just a handle, and the kernel-half of an object is looked up from the handle (just as file descriptors work in traditional Unix systems). Alta, on the other hand, can take advantage of the language protections provided by Java and can make data members "private"--which hides them from untrusted user code without denying access to trusted kernel code associated with the object. Besides avoiding the cost of looking up a kernel object for each user-mode object, this flexible protection allows other optimizations. For example, the Alta kernel can charge the cost of allocating kernel state to the user at the time the user-mode portion is created--which simplifies the kernel implementation. One final benefit of type safety is that user-visible kernel objects will always be correctly initialized before any operations are performed with them as the object's constructor is guaranteed to be invoked before the first usage. This constraint means code in the critical path does not need to check to make sure that an object is properly and completely initialized. Additionally, in Java, operations can be invoked only on legitimate objects, while in Fluke, a kernel operation can be invoked on any address and the kernel must verify the given address. Another compelling difference between Alta and Fluke is the ability to safely share objects between processes in Alta. While the benefits of this have yet to be fully demonstrated, it seems reasonable to assume that being able to access data directly--without IPC or object serialization--and safely will improve performance and enable new applications. Keep in mind that sharing Java objects is not simply sharing of raw data; sharing includes the code to access and manipulate the object, too. Additionally, type safety can be leveraged to mitigate one of the traditional weaknesses of capability systems: capability propagation. In a traditional capability system, if one process hands a capability to another process, the original owner of the capability has effectively lost control over the propagation of that capability. The recipient of a capability can pass it on to other processes without informing the original owner. In a type-safe system, the recipient of a capability could be trusted code that is impenetrable to the process that receives the capability. Assuming that only trusted code can access the capability in a child process, then additional guarantees can be made. For example, the trusted code could guarantee that only legitimate operations are invoked on the capability, or that operations are only invoked if sufficient resources are available in the client. The final distinction between Alta and Fluke is that Alta does not support state extraction for kernel objects, yet still provides an effective foundation for nested processes. As noted in sectionĀ3.2.7, Fluke kernel object state extraction is used for a comprehensive checkpointer, virtual memory servers, and process migration. The cost of this support, however, is a more complex kernel interface and implementation, specifically in the implementation of IPC and thread supportĀ[47]. Alta demonstrates that significant functionality--namely resource control--can be provided by the nested process model independent of support for total state extraction. 4.4.2 Performance comparisonThe Fluke benchmark results were obtained on the same machine used for measuring Alta, a 300Mhz Intel Pentium II. Two versions of Fluke are measured. First, the August 1996 version, which contains the IPC path copied into Alta. The second version is the January 1999 version of Fluke, which includes a revamped IPC framework and a number of optimizations to support user-mode kernel objectsĀ[18]. Note that the new version of Fluke supports two modes of execution for in-kernel threads, a stack-per-thread (process model) or stack-per-processor (interrupt model)Ā[21]. The interrupt model has a slight performance advantage, but the process model is the execution model used by Alta. Fluke was configured for process model execution when it was measured. TableĀ4.11
compares Alta and the two versions of Fluke in terms of primitive OS operations. Alta outperforms the old version of Fluke in all of the listed operations, except for Reference.compare(). Alta loses on this function call because Alta's Reference objects are correctly tracked by the object to which they point, and when a reference-able object is destroyed, all attached Reference objects are cleaned up. In contrast, Fluke's References can keep referenced objects "alive" even after those objects have been explicitly destroyed. This extra functionality requires an extra layer of locking in Alta--notice, though, that this extra locking does not unduly inflate the Port.reference() time. Additionally, Reference.compare() is implemented purely in Java and is thus hampered by the Kaffe JIT compiler. When compared to the newest version of Fluke, Alta loses out to Fluke's user-mode code optimizations. All of the operations that Fluke completes faster than a null system call are, obviously, wholly user-mode operations. All of these optimizations could, however, be incorporated into Alta, as they all rely on the fact that Fluke exposes noncritical parts of kernel objects to user mode; a fact that holds true for all kernel objects in Alta. Still, Alta is more than twice as fast at thread switching, and has a cheaper null system call. (Note that an Alta system call is on par with a synchronized method invocation, which takes 156 cycles.) Overall, Alta demonstrates reasonable performance for fundamental operations when compared to Fluke. For higher-level, more complex OS operations, Alta does not compare as well. TableĀ4.12
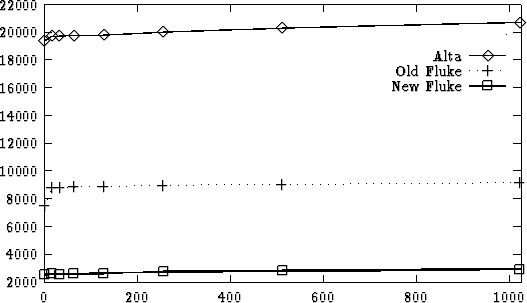
shows that for thread startup, process startup, and null IPC, Fluke outperforms Alta. Note that, in this table, the process start measurements are approximate, as they include some IPCs for transferring timestamps from the parent process to the child process. Figure
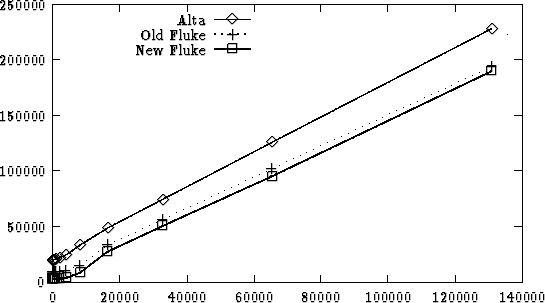
4.2 shows that while Alta's IPC is consistently slower than IPC in either version of Fluke, the difference is constant. FigureĀ4.3 shows that the gap between Alta and Fluke is constant for all reasonable data sizes. To get a better sense of why Alta IPC is three times slower than the old Fluke implementation's, TableĀ4.13 (p.Ā138) presents a breakdown similar to that presented in TableĀ4.6. This table includes a breakdown from the old Fluke IPC implementation. In this table, the differences between stages are comparable, except for stages 7, 8, 11, and 15, where Alta requires several thousand more cycles than Fluke to complete the stage. All four of these stages involve kernel-internal thread synchronization routines. In Alta this synchronization is written entirely in Java and duplicates functionality that is present in the virtual machine but which is not cleanly exposed to Java code; Alta could be modified to take advantage of this synchronization at a low level. Assuming this were the case, Alta would still be slower than Fluke because all the other stages of the IPC path are uniformly slower in Alta--ideally even this difference will diminish with improved Java compilation. 4.5 ConclusionAlta demonstrates the feasibility of hosting operating system abstractions designed for an MMU-based architecture in a system based around the type safety provided by Java. Alta demonstrates that while there are some shortcomings to Java as a systems programming language, they can be worked around cleanly. Creating new processes in Alta is expensive, but most of this cost can be attributed to the high cost of dynamic class control. Using a static definition of a process's typespace would simultaneously improve loading times, by completely avoiding frequent and costly IPC calls, and increase the set of interprocess-shareable classes. While recent versions of Fluke strikingly outperform Alta on a number of benchmarks, extending the JIT compiler to support inlining should bring these benefits to Alta, too. While an in-depth comparison between the performance of these two systems is hampered by the quality of the native code generator in Kaffe, the initial results look promising for the performance of Java based systems.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||