|
This chapter provides a brief introduction to Java and provides background on the design and development of Fluke's nested process model.
Java is an object-oriented, type-safe, garbage-collected language that directly supports synchronization, multithreading, and exceptions [32]. Java source code is generally compiled to bytecodes (pseudo-instructions for a virtual machine) that are verified and executed by a Java Virtual Machine [27]. Because of the type-safety provided by the language, compiler, and verifier, Java is a reasonable environment in which to run untrusted code. Just as the use of memory protection hardware by a standard operating system provides protection from a large class of malicious or buggy code, the Java language and the verifiers for compiled bytecodes provide a similar level of protection.
While Java is designed to provide enough safety to run untrusted programs, available implementations and parts of the design have well-known flaws [16, 40]. Other work is being done on improving bytecode verification [28, 39] and on other aspects of Java security [49]. For the purposes of this thesis, I assume that the verifier and interpreter do their jobs correctly. The implementation of Alta is based on a freely available JVM, Kaffe [51], which currently has neither a working verifier nor support for some of the language-level access controls.
Java applications run in an environment that has two basic components: the Java virtual machine [32] and the standard Java libraries [11, 12]. The virtual machine interprets or compiles bytecodes and provides threading and garbage collection. The standard Java libraries implement the various Java programming interfaces and standard services. Many of the classes in the standard Java libraries are implemented entirely in Java and are independent of the virtual machine. On the other hand, many of the core Java classes--those in the java.lang package--are tightly integrated with the implementation of the virtual machine. To access underlying system services, such as the file system or the network, classes must utilize native methods--methods that are not implemented in Java.
Because "Java" is both the name of the Virtual Machine interpreter/compiler and the language I will refer to the interpreter as the Java virtual machine or "JVM." When I use "Java" unadorned, I mean the language.
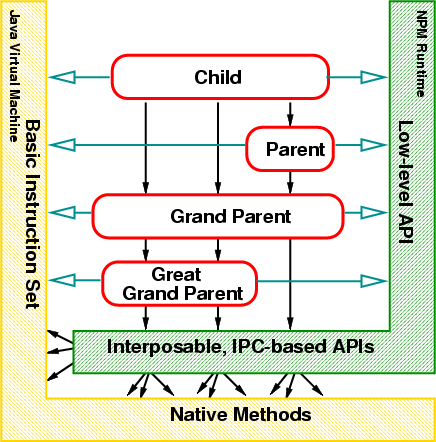
The Fluke nested process model is an architecture for organizing and controlling processes that compete for resources. Processes request services and resources from "ancestor" processes, which can grant, deny, or pass on requests. The model provides explicit, low-level support for the two most critical resources: memory and the CPU. More abstract resources, such as files, network access and processes, are controlled through a set of capability-based interfaces: capabilities are the basic mechanism for communication between processes. Figure 2.1
|
The nested process model is implemented in Fluke [22], a prototype microkernel written in C that supports POSIX-like processes that access high-level services through an IPC-based API; primitives and basic services such as synchronization and scheduling are provided directly by the kernel. Processes are separated by standard hardware memory protection--each process runs in its own address space. Because cross address-space communication is heavyweight, applications must provide a great deal of functionality for each cross-process invocation; thus, Fluke is a suitable environment for virtual memory management, process management, checkpointing, file systems, and other heavyweight services. What Fluke is not suitable for is small, communicative components that share complex data structures.
Processes in the nested process model can be "nested": a completely encapsulated process requests services and resources exclusively from its parent. Total encapsulation benefits the parent process, as it is assured of what resources the child process uses. Additionally, encapsulation enables the child process to manage its own children, while the parent is oblivious to the presence of anything more complex than a single child running within it. Nesting enables applications to contain whole hierarchies of processes, and for different applications to be composed together in a system.
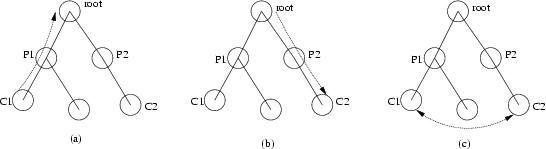
While the focus of the nested process model is hierarchical nesting and the notion of a hierarchy of processes is explicitly supported by the model, it is worth noting that interprocess communication need not follow the hierarchy. For example, in a system where a common ancestor process is willing to receive capabilities from child processes and hand them out to arbitrary children, then any processes in the system that can communicate with the ancestor process can get capabilities to communicate directly with each other. Figure 2.2
|
To support user-level virtual memory servers and flexible, user-level checkpointers [46], Fluke provides a mechanism for a process to extract the kernel "state" of any low-level object (see Section 3.2.7). It is not necessary that all actual kernel state be exported, but that any state not exported can be derived from state that is exported. For example, in Fluke a parent must be able to get enough state from a thread to create a new thread that is indistinguishable from the original. To support such state transparency, the kernel, in addition to providing all the state, must provide the state in a clean and timely fashion. For example, the kernel cannot suspend a parent process indefinitely while the parent accesses some state, as this would give a child some measure of control over its parent.
There are three distinct components of the nested process model programming interface. First is the basic instruction set in the underlying "machine"--hardware machine instructions (in Fluke) or virtual machine instructions (in Alta). The second component is the low-level programming interface that provides basic abstractions for managing memory and threads, plus the basic infrastructure for communication, sharing, and synchronization between processes. The third component is the set of high-level, interposable interfaces for standard OS abstractions. The first two components are always directly available to all applications, while the set of interposable interfaces available to an application is controlled by its ancestors.
The basic instruction set is usually predefined and cannot be modified to support the nested process model. The instruction set should not, however, contain instructions that operate on global state, as those operations will not be subject to interposition. For example, the mov instruction is allowable because it only affects the provided operands. On the other hand, instructions such as the Intel x86 gettsc instruction are not nestable because they return global information--in this case, a global notion of time.1 Generally, privileged instructions (such as I/O instructions) need to be made subject to interposition and should only be directly executed by the kernel.
The low-level API that provides the basic abstractions in the system has the same restrictions as the basic instruction set. Thus, all operations at this level operate only on provided state--that is, the operations manipulate state provided by the caller. (These operations may impact "global" kernel state, but only it is soft state and never directly visible outside the kernel.) Table
|
The third component, the IPC-based protocols, is where the nested process model resembles traditional capability-based systems and is where processes are able to exert control over other processes through interposition. Well-defined protocols should be amenable to flexible interposition (e.g., a process should not have to interpose on the memory interface if it only wants to interpose on file system access) and should match the style of high-level API used by system processes. In Fluke, for example, the IPC-based protocols are designed to support a POSIX-compatible standard C library. Appendix B provides more details on Alta's IPC-based protocols which were defined to match the requirements of the Java standard libraries.